Questo è un semplice strumento usato per estrarre il testo contenuto nei documenti PDF e salvarlo in un file di testo.
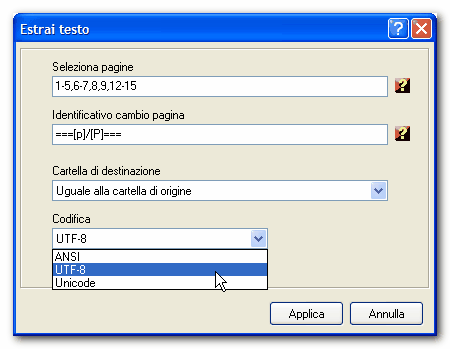
Nel campo Seleziona pagine inserisci i valori opportuni per l'estrazione del testo; non inserendo alcun valore, sarà estratto il testo da tutte le pagine che compongono il file PDF.

Il valore inserito nel campo Identificativo cambio
pagina è la stringa usata per evidenziare, nel
file di testo, il passaggio da una pagina ad un'altra.
Usa il valore [p] come riferimento al numero di pagina o il valore [P]
come riferimento alla totalità delle pagine.

Usa il campo Cartella di destinazione per specificare la destinazione dove salvare il file di testo.
Nel campo Codifica è possibile scegliere il tipo di codifica per il file di testo. Valori disponibili: ANSI, UTF8 e UNICODE.
Interfaccia da linea di comando:
| Nome funzione: | TextExtract |
| Opzioni: | [] - le due parentesi quadre definiscono il parametro come opzionale |
| [PageRange=] | - Definisce l'intervallo di pagine da cui estrarre il testo. Se non specificato, l'estrazione avviene da tutte le pagine. Per maggiori dettagli guarda l'immagine precedente. |
| [PageBreak=] | - Definisce la stringa da usare per evidenziare il cambio pagina. Inserisci [p] per scrivere il numero della pagina e [P] per scrivere il numero totale delle pagine. |
| [Encoding=] | - Codifica di output. 0 - ANSI 1 - UTF8 2 - Unicode |
| [OutputPath=] | - Percorso completo dove creare i files di testo. Se non specificato, il file verrà salvato nella cartella di origine del PDF. |
| [-s] | - Modalità silenziosa. Funziona senza visualizzare l'interfaccia (disponibile esclusivamente per le versioni licenziate). |
| FilesList | - Elenco di files PDF da cui estrarre il testo. Occorre separare i vari elementi con il carattere punto e virgola (;). Deve essere l'ultimo parametro da inserire |
| Esempio: "c:\Programmi\PDF–ShellTools\PDFShellTools.dll" TextExtract "pagerange=1,3-5" encoding=0 "pagebreak=-- [p]/[P]--" "c:\somefolder\file1.pdf;c:\somefolder\file2.pdf" |
|