C'est outil permet d'extraire le texte contenu dans les documents PDF vers un fichier texte.
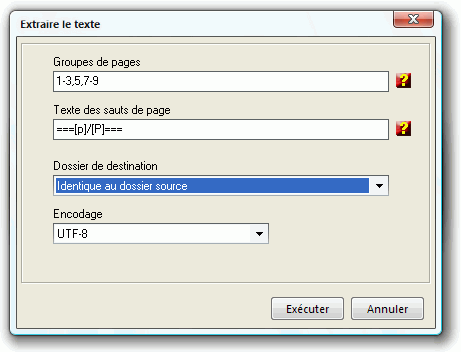
Le champ Groupes de pages permet de spécifier les pages à partir
desquelles le texte sera extrait, en utilisant les règles décrites
dans la Zone de Notification ci-dessous accessibles via
 à droite du champ; Laisser
ce champ vide pour extraire toutes les pages.
à droite du champ; Laisser
ce champ vide pour extraire toutes les pages.

Le champ Texte des sauts de page permet de signaler les sauts de page sous forme de caractères ou de texte. Entrer les caractères de contrôle [p] en référence au numéro de page et [P] en référence au numéro de page total.
Utiliser le champ Dossier de destination pour spécifier où sera sauvegarder le fichier texte.
L'option Encodage défini le format d'encodage des fichiers texte. Sélectionner ANSI, UTF8 ou UNICODE.
Interface de la ligne de commande :
| Nom de la fonction: | TextExtract |
| Options: | [] Paramètres optionnels |
| [PageRange=] | - - Définit des groupes de page du document d'où sera extrait le texte. Si rien n'est spécifié, extrait toutes les pages du document |
| [PageBreak=] | - Défini le texte utilisé pour signaler les sauts de pages. Insérer [p] pour écrire le numéro de page et [P] pour écrire le numéro de pages total |
| [Encoding=] | - Encodage du texte extrait 0 - ANSI 1 - UTF8 2 - Unicode |
| [OutputPath=] | - Arborescence complète où sera créer le fichier texte. Si non spécifié, l'arborescence du fichier source sera utilisé |
| [-s] | - mode muet. S'exécute sans faire apparaître l'interface (valable seulement pour les utilisateurs sous licence) |
| FilesList | - Liste de fichies d'où seront extrait le texte; Séparer les fichiers en utilisant la touche ";". Cette fonction doit être le dernier paramètre indiqué |
| Exemple: Rundll32 "c:\Program Files\PDF-ShellTools\PDFShellTools.dll",TextExtract "pagerange=1,3-5" encoding=0 "pagebreak=-- [p]/[P]--" "c:\somefolder\file1.pdf;c:\somefolder\file2.pdf" |
|