This is a simple tool used to extract a PDF document's text content into text files.
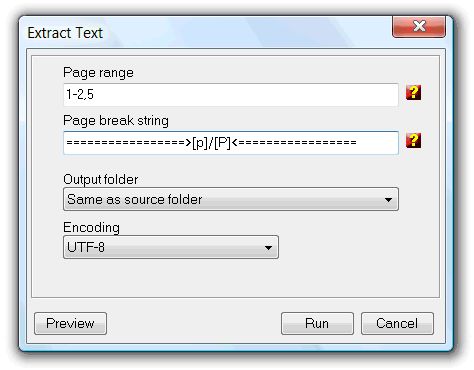
The Page range field is used to define the pages from where to extract text. Leave this field empty to extract from all.
The Page break string is the string used to signal a page break in the output text file. To make reference to the page number enter the [p] constant, and [P] to reference the total number of pages of the PDF.
Use the Output folder field to specify the output folder for the created text files.
The encoding option defines the text encoding standard used to encode the text files. Select from ANSI, UTF8 and UNICODE.
| Function name: | TextExtract |
| Options: | [] means optional parameter |
| [PagesRange=] | - Define the document pages range from where to extract text. If not specified, extract from all pages. Se above image for rules. |
| [PageBreak=] | - Define the string used to signal page breaks. Insert [p] to write page number and [P] to write the total number of pages. |
| [Encoding=] | - Text output encoding. 0 - ANSI 1 - UTF8 2 - Unicode |
| [OutputPath=] | - Full path where to create the text files. If not specified, the file source path is used instead. If this parameter includes also a file name, this will be the file name given to the text file (only useful for single file operations). Because of this, when passing only the output directory, it should end with a backslash character, e.g. OutputPath=C:\Temp\ |
| [-s] | - Silent mode. Run without showing the interface (only available for licensed users) |
| FilesList | - List of files to extract text from; Separate files using the semicolon";" char. Must be the last parameter |
| Example: "c:\Program Files\PDF-ShellTools\PDFShellTools.exe" TextExtract "pagesrange=1,3-5" encoding=0 "pagebreak=-- [p]/[P]--" "OutputPath=C:\My Text Files\\" "c:\somefolder\file1.pdf;c:\somefolder\file2.pdf" |
|