The Extract Images tool can extract image objects, or render document pages, to external image format files.
The tool has two modes of operation: Single file and batch mode. While in single file mode, when the tool is started selecting just one file, it presents the aspect shown in the next screenshot.
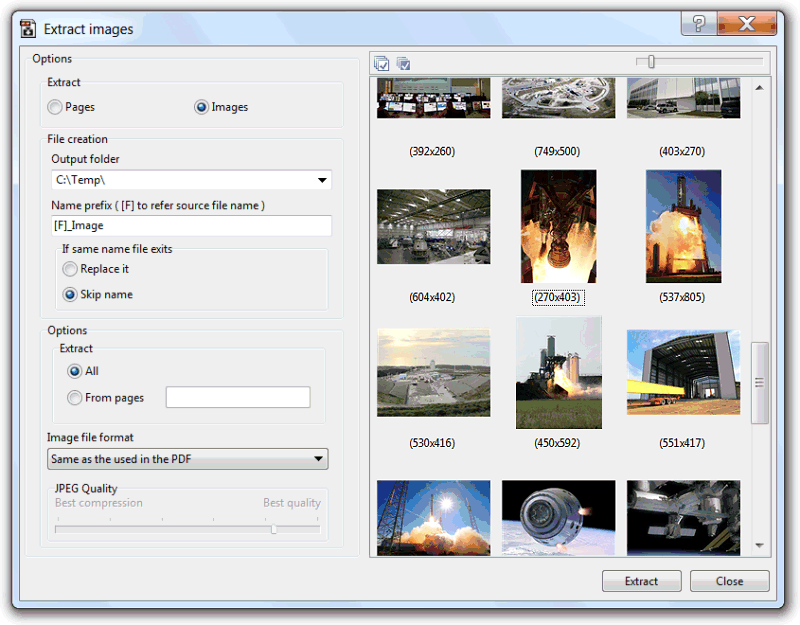
A left extract options panel, and a right images list view of all the image objects found, or rendered pages, of the submitted document. The images list view provides drag and drop and copy to clipboard functionality, to easily extract the needed image(s) to an external application or folder.
The extract options are straightforward. The top "Extract" section is used to define what images to extract. "Pages" to extract the rendering of the page's content, or "Images" to extract the PDF document image objects.
The "File creation" section is used to specify the output folder where the extracted images will be saved, the file name replace mode, if a name with the same name is found, and the name prefix. Image file names will be composed by this prefix concatenated with an automatically generated incremental number, and a file extension related to the image file format (NamePrefixXXXXX.ext). If the image prefix contains the [F] constant, the source file name will be used in that position, and the incremental number starts from zero for each document.
The "Options" section is used to define specific options related to the type of extraction, pages or images, being done.
For Pages we have DPIs, to specify the rendering resolution, and what pages to extract, all or custom defined range of pages (e.g. 1,3,5-10).
For images we can define to extract all or just from a specific range of pages, and the output image file format. The option "Same as the used in the PDF" will try to extract the image object without re-encoding, while all the other options, if internal format is different, will re-encode to that format.
If the tool is started with more than one document, it will run in batch mode, presenting only the left options panel, and not showing the right images list view.
| Function name: | ExtractImages |
| Options: | [] means optional parameter. |
| [OutputPath=] | - Full path where to create the extracted images files. Defaults to the PDF source folder. |
| [ExtractType=] | 0 - Full page render 1 - Image objects (default) |
| [NamePrefix=] | - The prefix to name the image files. Defaults to [F]_ |
| [-SkipName] | - If specified, prevents the overwrite of files with the same name. |
| [PagesRange=] | - Set the extraction to occur only from the specified pages. |
| [RenderDPIs=] | - The page render DPIs to use. Defaults to 72. Only used when ExtractType=0 |
| [ImageType=] | - The image save format. 0 - Same as the used in the PDF (default) 1 - Windows Bitmap (.bmp) 2 - JPEG (.jpg) 3 - Portable Network Graphics (.png) 4 - Graphics Interchange Format (.gif) |
| [JpegQuality=] | - When ImageType=2, sets the JPEG quality. Integer value between 10 and 100. |
| [-s] | - Silent mode. Run without showing the interface (only available for licensed users) |
| fileslist | - List of PDF files from where to extract images. Separate files using the semicolon ";" char. Wildcards supported. Must be the last parameter. |
| Example: "c:\Program Files\PDF-ShellTools\PDFShellTools.exe" ExtractImages NamePrefix=[F]_page PagesRange=1-5 ExtractType=0 C:\PDFs\*.PDF |
|