 PDF-Tekstonttrekken
PDF-Tekstonttrekken Dit is een eenvoudige tool om de tekstinhoud uit een PDF-document te onttrekken.
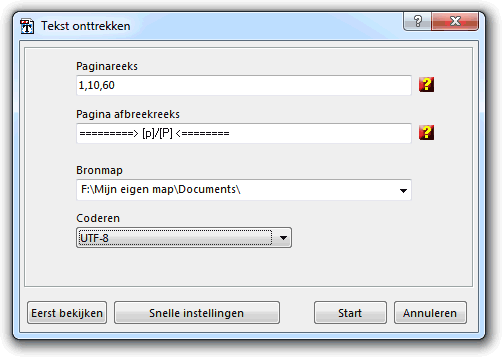
In het Paginareeks veld komen de pagina's te staan waaruit tekst moet worden onttrokken. Laat dit leeg, indien uit alle pagina's tekst moet worden onttrokken.
De Pagina-afbreekreeks is de reeks die wordt gebruikt om het paginaeinde aan te geven in het brontekstbestand. Om een verwijzing naar het paginanummer te maken vult u hier voor [p] het betreffende paginanummer in en om een verwijzing naar het totale aantal pagina's te maken vult u voor [P] dus het totaal in.
Gebruik het Bronmap veld om de bronmap/nieuwe map aan te geven voor de onttrokken bestanden.
De optie Coderen definieert de tekst die standaard wordt gebruikt om de tekstbestanden te coderen. Kies hiervoor uit ANSI, UTF8 en UNICODE.
| Functienaam: | TextExtract |
| Opties: | [] Optionele parameter |
| [PageRange=] | - Definieert de documentpagina's waaruit tekst moet worden onttrokken. Indien niet gespecificeerd, wordt uit alle pagina's onttrokken. Zie bovenstaande afbeelding voor de regels. |
| [PageBreak=] | - Definieert de reeks om de pagina's aan te geven. Een [p] invoegen om het paginanummer en een [P] om het totale aantal pagina's aan te geven. |
| [Encoding=] | - Tekstcodering. 0 - ANSI 1 - UTF8 2 - Unicode |
| [OutputPath=] | - Volledig pad waarin de onttrokken tekstbestanden worden opgeslagen. Indien niet gespecificeerd, wordt de bronmap gebruikt. |
| [-s] | - Stille modus. Uitvoering zonder verschijnen van de interface (alleen beschikbaar voor licentiehouders). |
| FilesList | - Lijst met PDF-bestanden voor tekstonttrekking. Bestandsscheiding door gebruik van punt/komma ";". Deze functie wordt gebruikt als laatste parameter. |
| Voorbeeld: Rundll32 "c:\Program Files\PDF-ShellTools\PDFShellTools.dll",TextExtract "pagerange=1,3-5" encoding=0 "pagebreak=-- [p]/[P]--" "c:\somefolder\file1.pdf;c:\somefolder\file2.pdf" |
|