It is activated clicking on File >Import and allows importation of data from a csv file. Successfully imported metadata will be added to the PDFE database, and to referenced document files itself, if selected to do so. Despite the fact csv means comma separated values, the list separator character correctly handles (maps) using the list separator character defined on the PC's regional settings, so it's system dependent. This is normally the semicolon ";", for regional settings that use the comma as decimal separator.
Handled CSV files must have the same characteristics of the ones created by the Export grid fields tool. Each line correspond to a document and each line must reference the file name and its path; they can also be merged in a single full path column.
The file to import may contain additional information, other than the metadata columns, such as disk label and disk serial, to better identify the referenced files. If these values are not present, the tool will use the ones from the disk letter the files path point to.
After choosing the .csv file to be imported, we will see the following import wizard dialog:
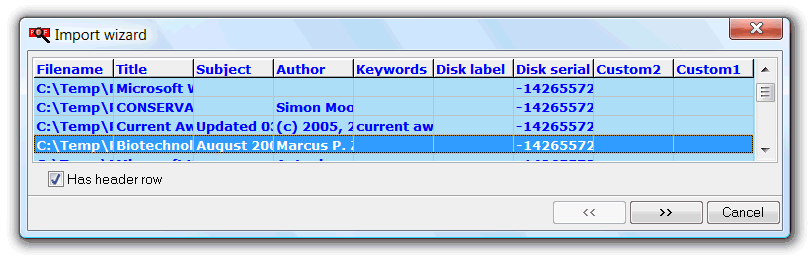
Now, we shall use the checkbox has header row to state whether the csv file has an header row or not. The software will try to understand on its own if an header row is present or not, comparing the first csv row items to the current grid layout column captions. Because this operation may fail, it's important to manually check this option, or first valid row will not be correctly determined, if indeed a header exists and tool fail to identify it.
Clicking on the >> button, the next import wizard page will show up. It's used to set the correspondences between each source file data column and the PDF Explorer supported metadata fields.
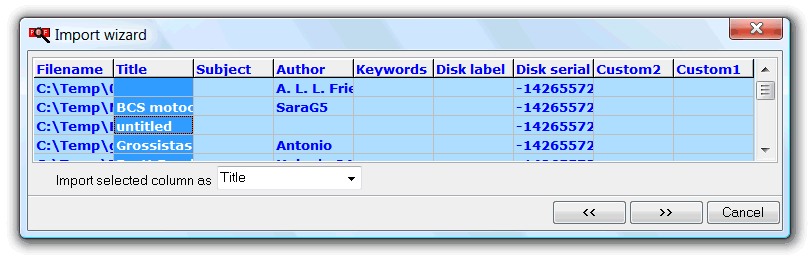
If source file data columns have an header named as the active grid layout columns, the software will set automatically the initial correspondence. At each >> button click, active column will advance, and selected columns map will be show at on the Import selected column as selector. If wrong, we just need to select another one from the list.
When all done, next page will appear if errors found, or a warning message exist, after tool check if import operation can proceed. Next image show an impossible to happen errors panel, used here only to show all the warning and error messages that can appear.
 :
:
1st Error message - No correctly mapped columns found. The import operation can't continue.
2nd Error message - It was not possible to construct a files complete path (unmapped file name and path, or full path, columns). The import operation can't continue.
1st Warning message - Some fields required to identify the source disk (serial number and disk label) not referenced. The import process can continue, but these values will be imported from files path pointed disk.
2nd Warning message - Appear If imported file references don't contain all the PDFE supported metadata fields, and this file reference doesn't exists already on the PDFE database. Not imported fields will be left empty. The import process could go on.
If no errors found, we will reach this last import wizard page:
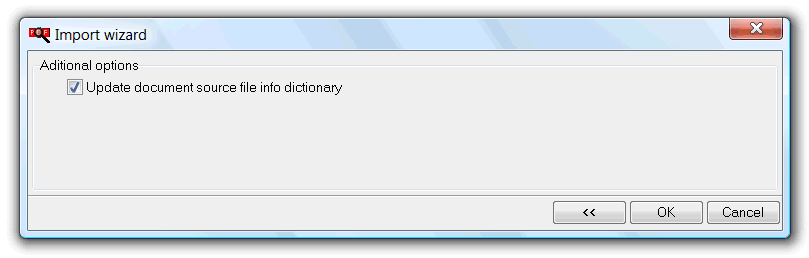
The update document source file info dictionary check box is used, if checked, to also edit imported referenced files with imported metadata.
Finally we can start the import process, clicking the OK button. Import wizard will pass import operation to the batch tool interface, showing the batch tool input/output screen, where we can check the import progress, or stop the operation. After the process is finished, the Workgrid will be filled with all the successfully imported file references.
Exporting a filled grid to a csv file, externally edit it using a csv file compatible tool, and later use this import wizard to import the edited metadata, is one powerful technique that enable actions such as: import external databases metadata, use script tools to automate the edition, etc.