Toto je jednoduchý nástroj užívaný pro vytažení textového obsahu z PDF dokumentů do textového souboru.
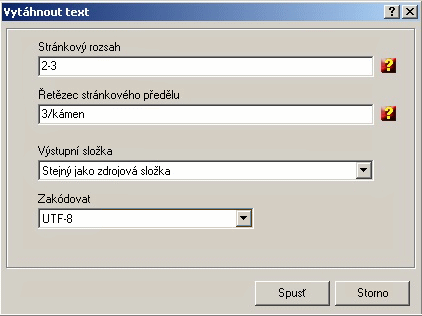
V poli Stránkový rozsah zadáme rozsah stran, ze kterých chceme vytáhnout text, pokud nezadáme rozsah, bude vybráno všechno.
Řetězec stránkového předělu je řetězec, který signalizuje stránkový předěl ve výstupním textovém souboru. První položka může být odkaz na číslo stránky [p] a za lomítkem uvedeno [P] kontrolní slovo.
V řádku Výstupní složka zadáme cestu ke složce, kam chceme uložit vytvořený textový soubor.
V posledním poli vybereme kódování, standardně užívané pro textové soubory. Vyberte z ANSI, UTF8 a UNICODE.
| Příkaz: | TextExtract |
| Možnosti: | [] nepovinný parametr |
| [PageRange=] | - Definovat rozsah stran dokumentu odkud vytáhnout text. Pokud pole nevyplníte, vybere text ze všech stran. Pravidla v nápovědních bublinách. |
| [PageBreak=] | - Definujeme řetězec použitý pro hranice výběru. Vložíme [p] číslo stránky a [P] úhrn počtu stran. |
| [Encoding=] | - Kódování textu. 0 - ANSI 1 - UTF8 2 - Unicode |
| [OutputPath=] | - Cesta kam chceme uložit vytvořené textové soubory. Jestliže nezadáme, bude text uložen ve zdrojové složce souboru. |
| [-s] | - Skrytý chod. Bez zadávání do příkazového řádku (jen pro registrované uživatele) |
| FilesList | - Seznam souborů pro zvolenou operaci; K oddělení používejte středník ";" i konec výběru musí být ukončen středníkem. |
| Příklad: Rundll32 "c:\Program Files\PDF-ShellTools\PDFShellTools.dll",TextExtract "pagerange=1,3-5" encoding=0 "pagebreak=-- [p]/[P]--" "c:\somefolder\file1.pdf;c:\somefolder\file2.pdf" |
|