This search and extract tool provides a collection of tools to extract information from PDFs, and export it to an external text or .csv file, or into its metadata info fields.
Currently there are two tools, one that uses the power of regular expressions to search and extract from the documents text content, and one that extract documents page media size information.
The Search in text content is a tool that runs a user defined regular expression against the document text content, exporting the text that validate the regular expressions rules to the user defined document metadata fields, or to an external text or .csv file.
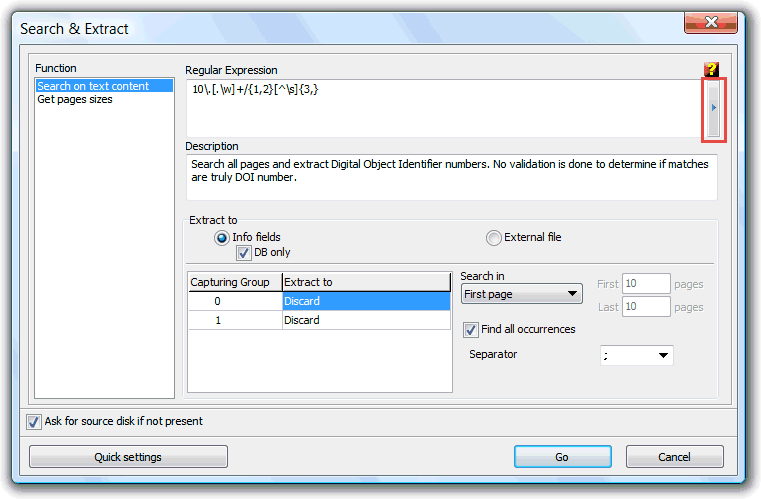
Regular expressions are a very advanced text search technique that validate user defined pattern rules to the text being processed, in order to isolate and extract text with the required characteristics. Regular expressions syntax is a very exhaustive subject, not discussed here. Even so, there is plenty information about this subject on the Internet.
Because this technique works with text patterns, this tool is useful for when we have more than one document with same text content characteristics, making it possible to define a regular expression, valid for all. Defining a regular expression that is able to extract a given text pattern is a difficult task, and in some cases impossible. Definitively, not easy for inexperienced users.
The above image red rectangle enclosed button, the library button, provides access to some default defined, regular expression, to extract ISBN and DOI numbers, and e-mail and URL addresses, so this can be a useful tool even for those who don't want to start learning regular expressions.
The other tool, the Get pages sizes, is used to extract PDF documents pages media sizes information. A PDF document page can have defined a set of different page boundaries, used to define the page size and some other more technical boundaries employed to conform the page content.
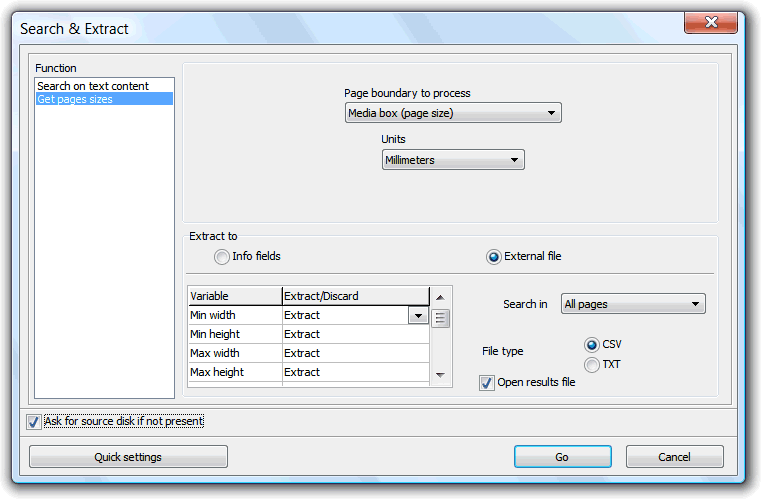
Because same PDF document can have more than one page size, the tool will extract the minimum, maximum and average values of these boxes width and height variables, and also the total area of that selected to extract boundary box. There is also the possibility to define the units to use and to where to extract these values (to the document metadata fields, or to an external text or .csv file).