本功能可以擷取PDF文件中的文字內容,存成純文字檔。
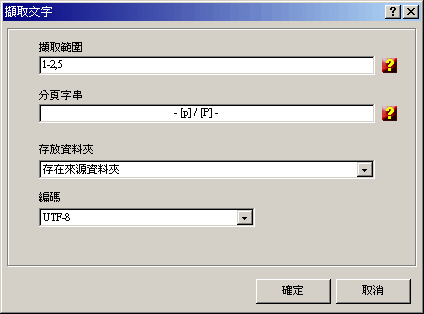
請在「擷取範圍」中可指定要擷取的頁次,若保持空白則擷取全部頁次。
請在「分頁字串」中輸入用來分隔頁面的字串,並可使用[p]代表頁次、使用[P]代表總頁數。
請使用「存放資料夾」指定新產生檔案的存放資料夾。
請在「編碼」指定純文字檔的編碼標準:ANSI、UTF8、UNICODE。
| Function name: | TextExtract |
| Options: | 有[ ]者是選擇性的參數 |
| [PageRange=] | - 指定擷取文字的頁面範圍。若未指定,則擷取所有頁面的文字。語法請見上圖所示。 |
| [PageBreak=] | - 指定「分頁字串」,可使用[p]代表頁次、使用[P]代表總頁數。 |
| [Encoding=] | - 指定純文字檔的編碼標準 0 - ANSI 1 - UTF8 2 - Unicode |
| [OutputPath=] | - 新產生純文字檔的完整存放路徑。如果未指定,便存放於來源檔案的資料夾。 |
| [-s] | - 無訊息模式,不顯示執行介面(只開放給註冊使用者)。 |
| FilesList | - 要擷取文字內容的PDF文件。請使用分號(;)來區隔每個PDF文件。此參數必須為最後一個參數。 |
| 範例: Rundll32 "c:\Program Files\PDF-ShellTools\PDFShellTools.dll",TextExtract "pagerange=1,3-5" encoding=0 "pagebreak=-- [p]/[P]--" "c:\somefolder\file1.PDF;c:\somefolder\file2.PDF" |
|