这是一个用来提取PDF文件中的文本内容的简单工具。
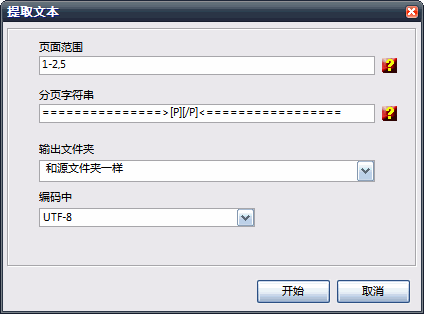
页面范围(Page range) 区域可以输入想要提取文本的页码,留空则默认为全文提取。
页面分割字符串(Page break string )区域可以指定输出文本中用来标示页面分割的字符串。可以使用 [p]控制字指代所在的页码,[P]指代总页数。
使用输出目录(Output folder )选项框可以指定提取出的文本文件保存的目录位置。
编码选项框可以指定文本的编码标准,可以在ANSI, UTF8 和 UNICODE之间选择。
| 功能名称: | TextExtract |
| 选项: | [] 内为可选参数 |
| [PageRange=] | 定义要提取文本的页码范围。 如果没有提供,则提取所有页面。 关于页面定义规则,请参看上图。 |
| [PageBreak=] | 定义分割页面的字符串,使用[p]插入页码,[P]插入总页数。 |
| [Encoding=] | - 输出文本的编码方式. 0 - ANSI 1 - UTF8 2 - Unicode |
| [OutputPath=] | 存放所建立的文本文件的目录的完整路经。如果没有指定,则使用和源文件相同的目录。 |
| [-s] | 安静模式. 运行时不显示执行窗口,(只对注册用户可用)。 |
| FilesList | PDF文件列表; 使用分号";"分割各个PDF文件. 必须为最后一个参数。 |
| 示例: Rundll32 "c:\Program Files\PDF-ShellTools\PDFShellTools.dll",TextExtract "pagerange=1,3-5" encoding=0 "pagebreak=-- [p]/[P]--" "c:\somefolder\file1.PDF;c:\somefolder\file2.PDF" |
|