This tool is used to split, or extract pages, from PDF documents, so that a new PDF document will be created with the pages extracted. With the powerful split rules interpreter we can easily specify the pages, or the range of pages, we want to extract.
In the Split/Extract rules edit box we shall type the expression that defines the split operation we want to be performed on the files submitted to this tool.
The split rules syntax to be used can be reached, at any time, through the yellow question mark on the top right. Move the mouse pointer over it, and the image, shown below, will appear.

The output folder field is used to specify the folder where the new files will be created. By default it is filled with the source of files folder.
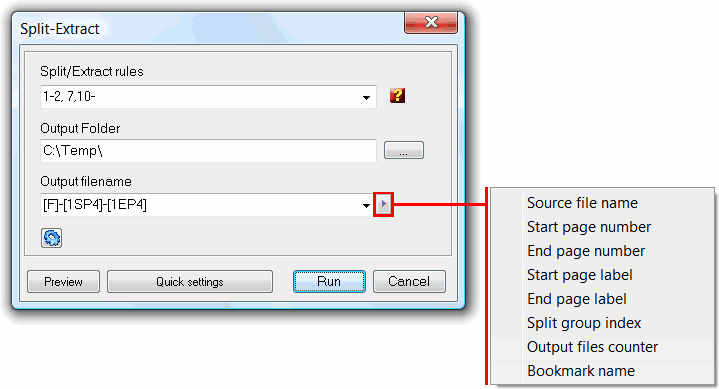
The output filename field is used to specify the output filename composition expression. Using some constants, quickly entered using the at right popup menu, as shown in the above tool screenshot, it is possible to make the output filename dynamic in a way that expresses the split operation that produced it.
Supported constants:
[F] - To reference the split source file name.
[1SP4] - To reference the source file name start page index the generated file has as first page. The left 1 is optional, can be any positive integer number, and it's used to offset this index. The right 4 can be any integer number, and it is used to specify the 0 padding to the desired size.
[1EP4] - As the previous one, but to the reference the last page index contained in the output file.
[1SPL4] - This reference the start page label. Each page in a PDF document is identified by an integer page index that expresses the page’s relative position within the document, the one referenced with the two above constants. In addition, a document may optionally define page labels to identify each page visually on the screen or in print. Page labels and page indices need not coincide: the indices are fixed, running consecutively through the document starting from 0 for the first page, but the labels can be specified in any way that is appropriate for the particular document. For example, if the document begins with 12 pages of front matter numbered in roman numerals and the remainder of the document is numbered in Arabic, the first page would have a page index of 0 and a page label of i, the twelfth page would have index 11 and label xii, and the thirteenth page would have index 12 and label 1. The constant optional left number and right number have the same function as for the start and end page index constants, but in here are only used if the page label is numeric only.
[1EPL4] - As the previous one, but to the reference the last page label contained in the output file.
[GI] - To reference the split group index. When defining the split rule we can define more that one group of rules, separating these groups with the semicolon ';' character. This groups are treated as individual and result always in separated documents. 1-5,10; 6-8,10 : Two split groups. First will result in a PDF with pages 1 to 5 and 10 (split group index variable equal to 1), and a second PDF with pages 6 to 8 and 10 (split group index variable equal to 2). odd; even : we get a PDF with all the odd pages, and another with all the even pages. The "split group index" variable will be 1 for the "odd" rule and 2 for the "even" rule. With this variable we can reflect this group index in the output filename.
[1FC4] - To reference the number of output files already created, within the current split group.
[BN] - Used only when splitting by top-level bookmarks, to reference the bookmark name.