With this tool we can extract image objects, or render document pages, to external image format files.
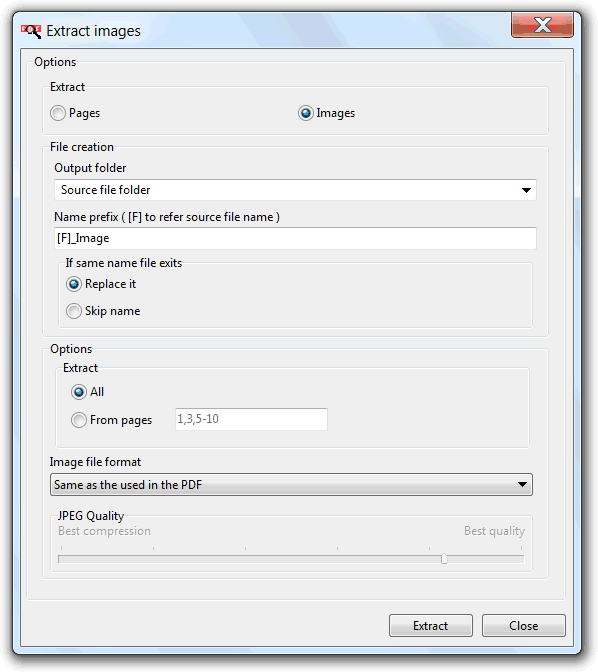
The extract options are straightforward. The top "Extract" section is used to define what images to extract. "Pages" to extract the rendering of the pages content, or "Images" to extract the PDF document image objects.
The "File creation" section is used to specify the output folder where the extracted images will be saved, the file name replace mode, if a name with the same name is found, and the name prefix. Image file names will be composed by this prefix concatenated with an automatically generated incremental number, and a file extension related to the image file format (NamePrefixXXXXX.ext). If the image prefix contains the [F] constant, the source file name will be used in that position, and the incremental number starts from zero for each document.
The "Options" section is used to define specific options related to the type of extraction, pages or images, being done.
For Pages we have DPIs, to specify the rendering resolution, and what pages to extract, all or custom defined range of pages (e.g. 1,3,5-10).
For images we can define to extract all or just from a specific range of pages, and the output image file format. The option "Same as the used in the PDF" will try to extract the image object without re-encoding, while all the other options, if internal format is different, will re-encode to that format.